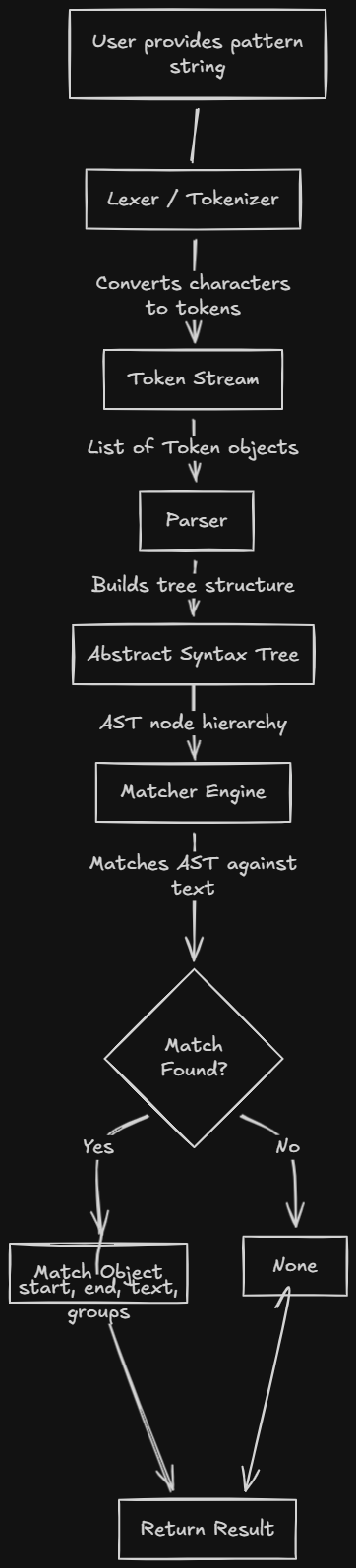
In this article we'll build a simple regular expression engine in Go. It will support patterns like a*b, (ab)+, and \\d+ and expose both full match and search. The article is divided into 3 sections:
- →Lexing — turn the pattern string into a token stream
- →Parsing — build an AST from tokens
- →Matching — run the AST against input text
A similar, NFA-based approach is covered in How to build a regex engine from scratch (Thompson's construction); here we use a recursive-descent parser and an AST-walking matcher.
Lexing
On its own, a regex string is just a string. We need to transform it into something with structure: a stream of tokens. For example:
- →Original:
"a*b|(c+)" - →Tokens:
CHAR('a'),STAR,CHAR('b'),PIPE,LPAREN,CHAR('c'),PLUS,RPAREN,EOF
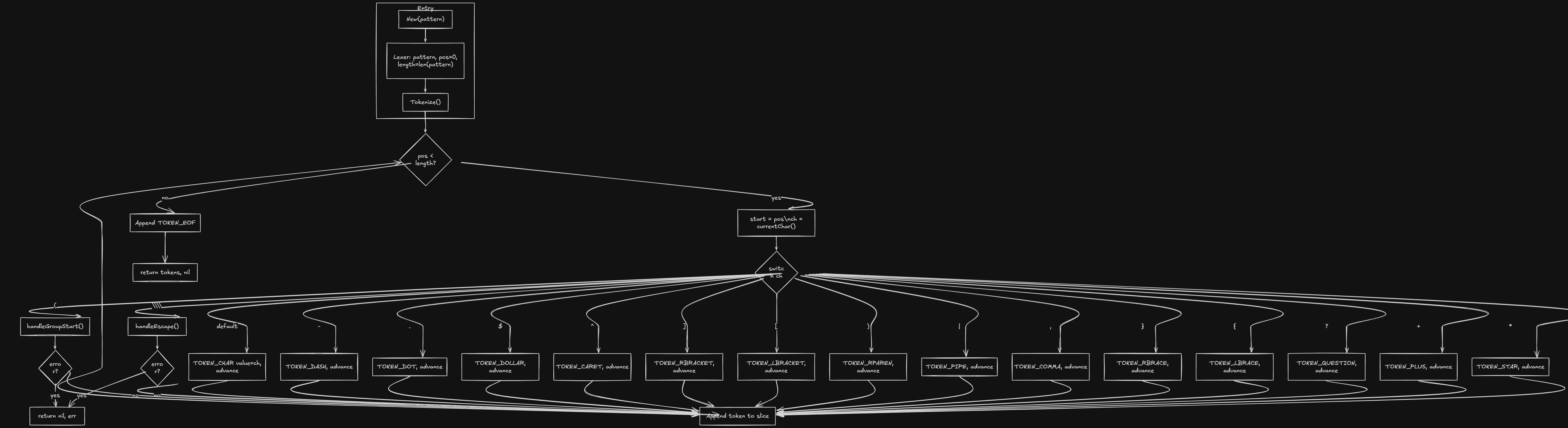
The core idea is simple: we scan the pattern character by character, recognize special symbols (* + ? ( ) [ ] | \\ { }, etc.), and emit the right token. Everything else is a literal character.
Token types and lexer state
We define token types as constants and a Token struct that holds the type, the value (e.g. the character or quantifier text), and the position for error reporting.
goconst ( TOKEN_CHAR TokenType = iota TOKEN_STAR TOKEN_PLUS TOKEN_QUESTION TOKEN_LBRACE TOKEN_RBRACE TOKEN_COMMA TOKEN_PIPE TOKEN_LPAREN TOKEN_RPAREN TOKEN_LBRACKET TOKEN_RBRACKET TOKEN_DOT TOKEN_DOLLAR TOKEN_BACKSLASH TOKEN_DIGIT TOKEN_WORD TOKEN_WHITESPACE // ... TOKEN_EOF etc. ) type Token struct { Type TokenType Value string Position int } type Lexer struct { pattern string pos int length int }
The main loop
We loop until we've consumed the whole pattern. For each character we dispatch: special characters become a single token; \\ triggers escape handling; anything else is TOKEN_CHAR.
gofunc (l *Lexer) Tokenize() ([]Token, error) { var tokens []Token for l.pos < l.length { start := l.pos ch := l.currentChar() switch ch { case '\\': tok, err := l.handleEscape() if err != nil { return nil, err } tokens = append(tokens, tok) case '*': tokens = append(tokens, Token{TOKEN_STAR, "*", start}) l.advance() case '+': tokens = append(tokens, Token{TOKEN_PLUS, "+", start}) l.advance() case '?': tokens = append(tokens, Token{TOKEN_QUESTION, "?", start}) l.advance() case '|': tokens = append(tokens, Token{TOKEN_PIPE, "|", start}) l.advance() case '(', ')', '.', '[', ']', '^', '$', '-', ',', '{', '}': // emit corresponding token, advance default: tokens = append(tokens, Token{TOKEN_CHAR, string(ch), start}) l.advance() } } tokens = append(tokens, Token{TOKEN_EOF, "", l.pos}) return tokens, nil }

Handling escapes and groups
- →
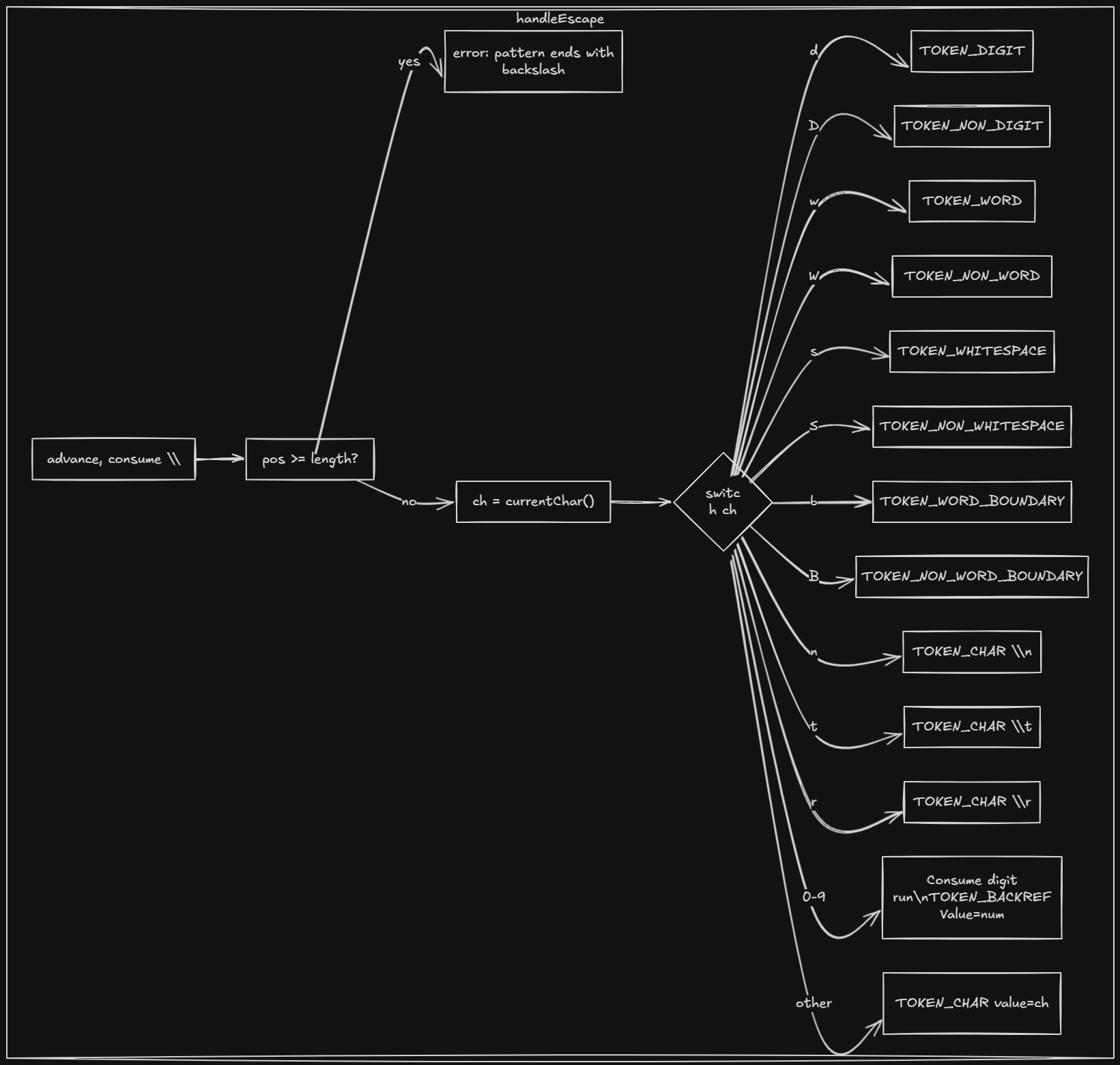
handleEscape— Consume the backslash and the next character. For\\d,\\D,\\w,\\W,\\s,\\Swe emit predefined-class tokens. For\\n,\\t,\\rwe emit a literal. For\\+or\\*we strip the special meaning and emitTOKEN_CHAR. For\\1,\\2etc. we emit backreference tokens.
- →
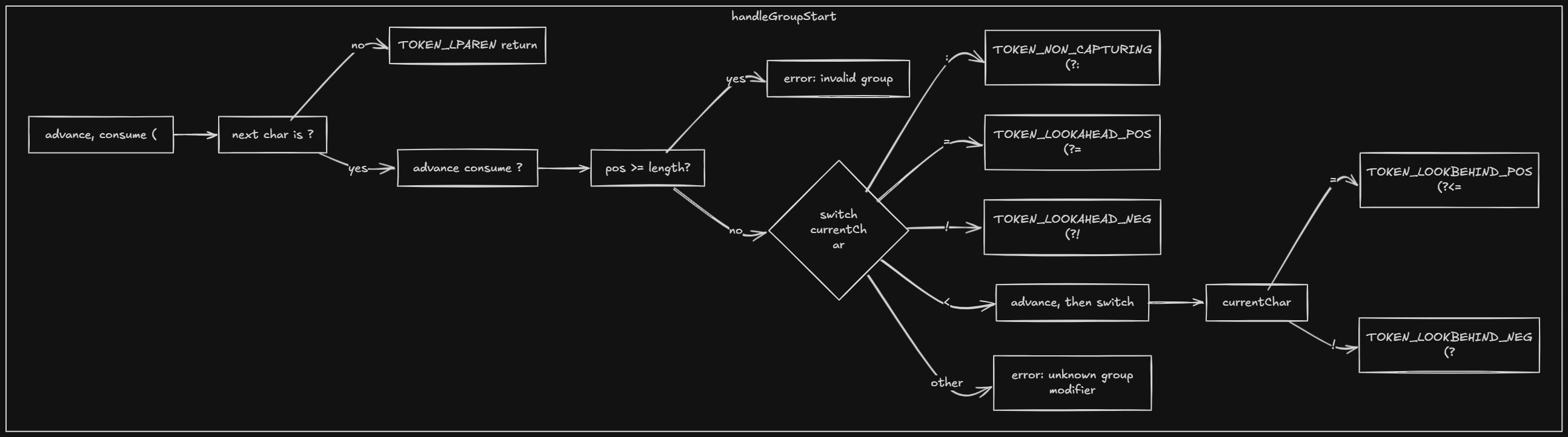
handleGroupStart— After(, we look ahead for?:(non-capturing),?=/?!(lookahead),?<=/?<!(lookbehind), or else treat it as a capturing group and emit the appropriate token.
Once we have the token stream, the next step is to give it a tree shape.
Parsing
We now have a list of tokens. We need to turn them into an abstract syntax tree (AST). The parser is recursive descent: we define the grammar and implement one function per rule.
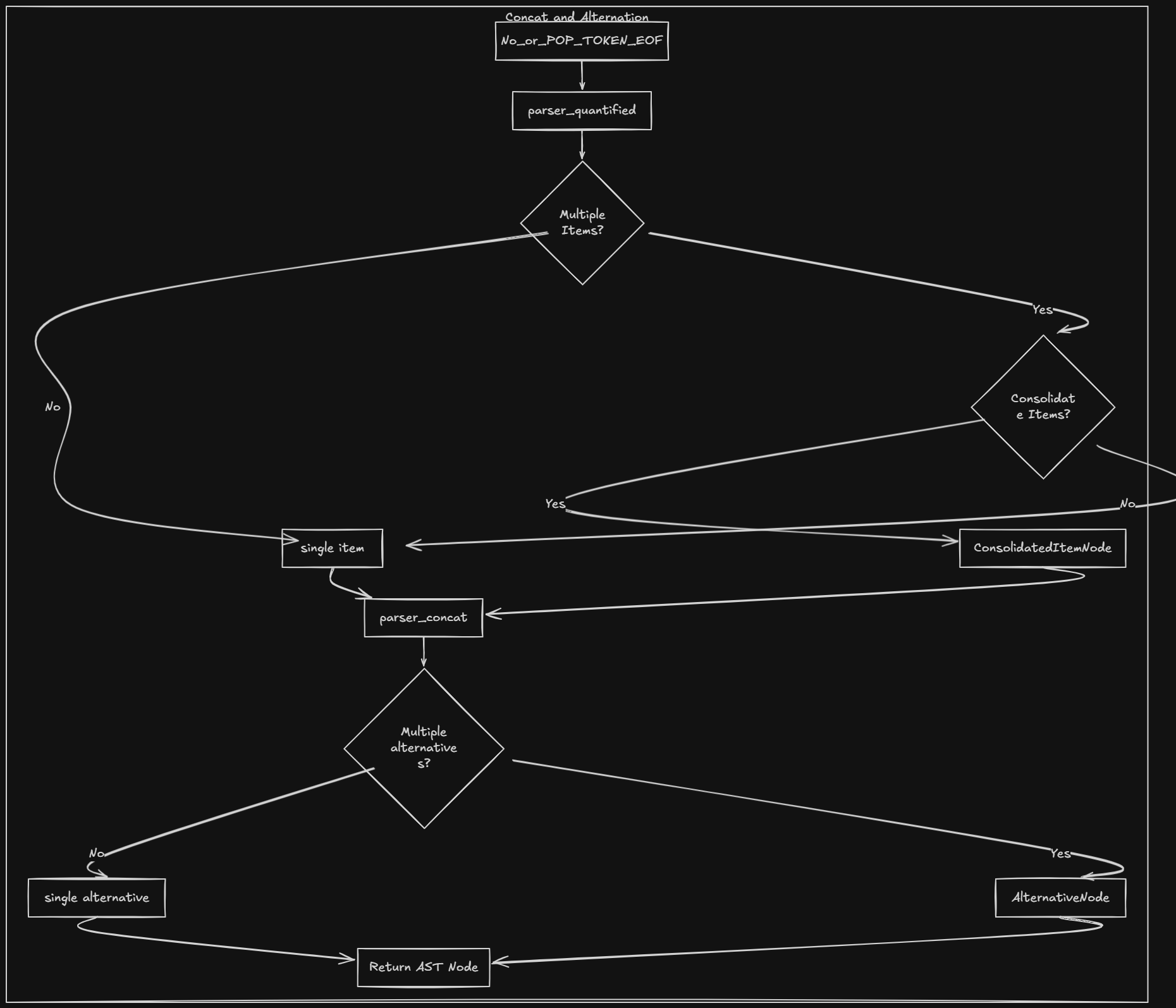
Grammar (in spirit)
- →alternation → concat (
|concat)* - →concat → quantified+
- →quantified → atom quantifier? (quantifier is
*,+,?, or{n}/{n,}/{n,m}) - →atom → char | dot | predefined class |
(alternation)|(?:alternation)
So alternation has the lowest precedence (we split on | last), then concatenation (sequence of quantified pieces), then quantifiers (attach to a single atom).
Entry point and alternation
Parse() returns the root AST node. We parse one alternation and then insist we're at EOF.
gofunc (p *Parser) Parse() ast.Node { node := p.parseAlternation() if p.current().Type != lexer.TOKEN_EOF { panic("unexpected token") } return node } func (p *Parser) parseAlternation() ast.Node { nodes := []ast.Node{p.parseConcat()} for p.current().Type == lexer.TOKEN_PIPE { p.advance() nodes = append(nodes, p.parseConcat()) } if len(nodes) == 1 { return nodes[0] } return &ast.AlternationNode{Alternatives: nodes} }
- →We collect one or more
parseConcat()results separated by|. - →If there's only one, we return it as-is; otherwise we wrap them in an
AlternationNode.
Concatenation and quantified atoms
gofunc (p *Parser) parseConcat() ast.Node { var nodes []ast.Node for { tok := p.current() if tok.Type == lexer.TOKEN_PIPE || tok.Type == lexer.TOKEN_RPAREN || tok.Type == lexer.TOKEN_EOF { break } nodes = append(nodes, p.parseQuantified()) } if len(nodes) == 1 { return nodes[0] } return &ast.ConcatNode{Children: nodes} } func (p *Parser) parseQuantified() ast.Node { atom := p.parseAtom() tok := p.current() switch tok.Type { case lexer.TOKEN_STAR: p.advance() return &ast.QuantifierNode{Child: atom, Min: 0, Max: nil, Greedy: true} case lexer.TOKEN_PLUS: p.advance() return &ast.QuantifierNode{Child: atom, Min: 1, Max: nil, Greedy: true} case lexer.TOKEN_QUESTION: p.advance() maxOne := 1 return &ast.QuantifierNode{Child: atom, Min: 0, Max: &maxOne, Greedy: true} case lexer.TOKEN_LBRACE: // parse {n}, {n,}, {n,m} and return QuantifierNode default: return atom } }
- →
parseConcatkeeps callingparseQuantifieduntil we hit|,), or EOF; it wraps two or more children in aConcatNode. - →
parseQuantifiedparses one atom, then optionally consumes a quantifier and wraps the atom in aQuantifierNodewith min/max.
Atoms are single characters (CharNode), dot (DotNode), predefined classes (PredefinedClassNode), or groups. For ( we call parseAlternation again and wrap the result in GroupNode (with a group number for captures) or NonCapturingGroupNode.
Matching
The final piece is matching: we take the AST and the input string and decide if (and where) the pattern matches.
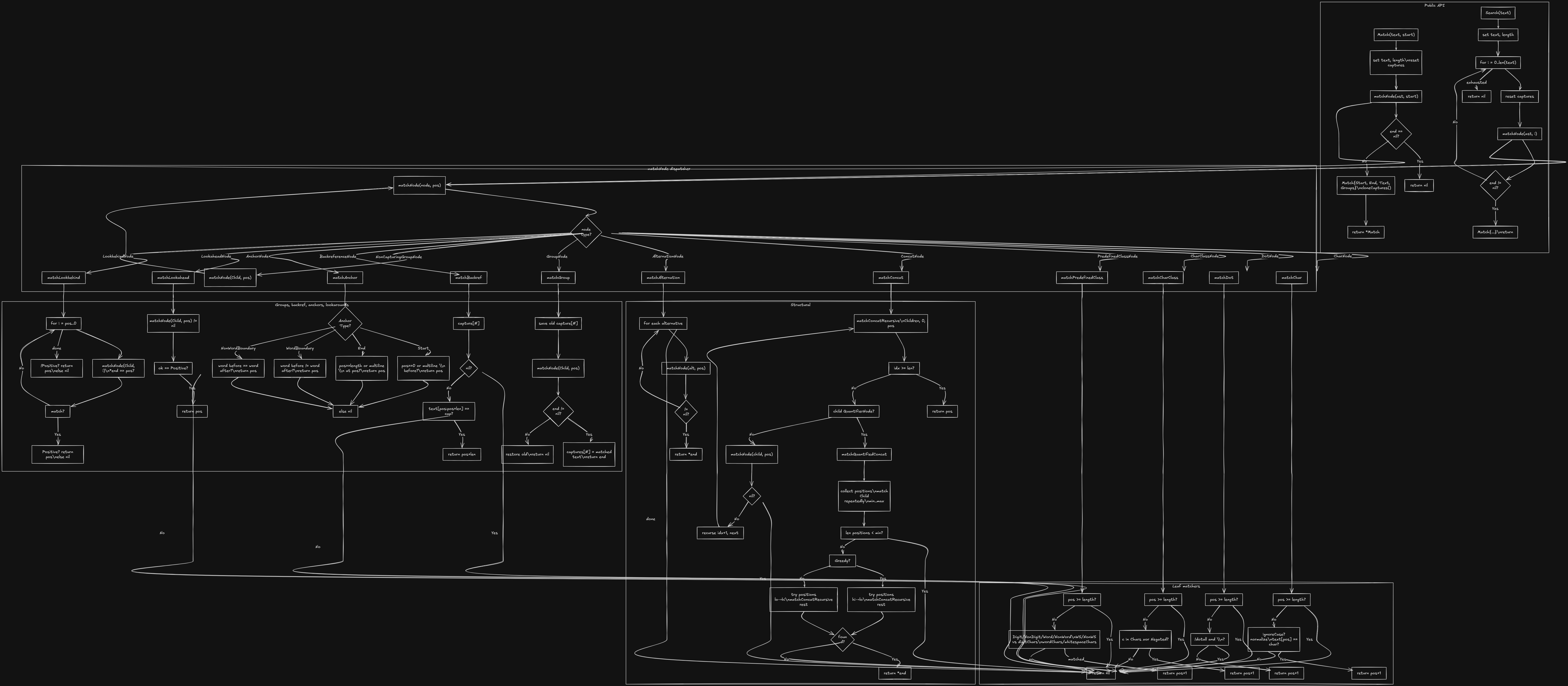
Match vs Search
- →Match(text, start) — Try to match the pattern starting at index
start. The match must consume a contiguous segment; we return aMatchwithStart,End,Text, andGroups, ornilif it doesn't match. - →Search(text) — Find the first occurrence anywhere. We try
Match(text, 0), thenMatch(text, 1), and so on until we get a match or run out of positions.
Matcher state and API
gotype Match struct { Start int End int Text string Groups map[int]*string } type Matcher struct { ast ast.Node text string length int captures map[int]*string ignoreCase bool // ... } func (m *Matcher) Match(text string, start int) *Match { m.text = text m.length = len(text) m.captures = make(map[int]*string) end := m.matchNode(m.ast, start) if end == nil { return nil } return &Match{Start: start, End: *end, Text: text[start:*end], Groups: m.cloneCaptures()} } func (m *Matcher) Search(text string) *Match { for i := 0; i <= len(text); i++ { m.captures = make(map[int]*string) if end := m.matchNode(m.ast, i); end != nil { return &Match{Start: i, End: *end, Text: text[i:*end], Groups: m.cloneCaptures()} } } return nil }
How matchNode works
matchNode(node, start) returns a pointer to the end index if the subtree matches text[start:...], or nil on failure. We switch on the node type:
- →CharNode — If
text[start]equals the character (subject toignoreCase), returnstart+1. - →DotNode — Match any character (except newline unless
dotall); returnstart+1. - →PredefinedClassNode — Check if
text[start]is in\\d,\\w,\\s, etc.; returnstart+1ornil. - →ConcatNode — Match the first child from
start; if it returnsend1, match the next child fromend1; continue until all children match. Return the final end index. - →AlternationNode — Try each alternative in order; return the first successful
matchNoderesult. - →QuantifierNode — Try to match the child
mintomaxtimes (backtracking if greedy whenmaxis unbounded). - →GroupNode — Match the child, and if it succeeds, store the matched span in
captures[groupNumber]before returning.
So the whole engine is: pattern string → Lexer → tokens → Parser → AST → Matcher → Match or nil.
CLI and library usage
Build and run from the project root:
bashgo build -o regex ./cmd/regex ./regex "<pattern>" "<text>" [text ...]
For each text argument the CLI tries a full match from the start; if that fails it runs a search and prints the first match or "No match".
Using the engine as a library:
gol := lexer.New(`a*b`) tokens, err := l.Tokenize() if err != nil { /* ... */ } p := parser.New(tokens) root := p.Parse() m := matcher.New(root, nil) if match := m.Match("aaab", 0); match != nil { // match.Text, match.Start, match.End, match.Groups } if match := m.Search("xaaab"); match != nil { // first occurrence }
Supported syntax (end-to-end)
| Feature | Example |
|---|---|
| Literals | abc |
| Dot | . (any char except newline) |
| Quantifiers | * + ? {n} {n,} {n,m} |
| Alternation | `a |
| Groups | (ab) capturing, (?:ab) non-capturing |
| Predefined classes | \d \D \w \W \s \S |
| Escapes | \n \t \r \+ etc. |
Limitations and next steps
Anchors (^ $) and character classes [a-z] are lexed and have matcher support but are not yet wired through the parser. Backreferences and lookarounds exist in the AST and matcher but are not fully integrated. Parser errors currently panic. Natural next steps: extend the parser for character classes and anchors, and replace panics with error returns.
References
- →How to build a regex engine from scratch — NFA-based approach in Go (Thompson's construction)
- →Thompson's construction — Wikipedia
- →Regular expression — Wikipedia
- →Implementing a regular expression engine — Denis Kyashif